Activation Functions — Deep Learning
Introduction
Neural network may contain n number of hidden layers with each layer containing n number of neurons. A neuron’s job is to calculate the sum of all the inputs to the neuron multiplied with their respective weights. And it has to apply some activation function to the end result. But why do they need an activation function?
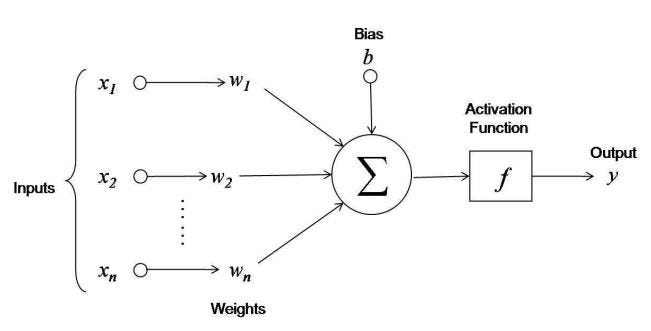
Because you have calculated the weighted sum of inputs and added bias. Now the Y value has no bound and we need to restrict the y value to a certain range.
Example:
You are running a binary classifier and the model should predict whether the output is cat or not. If the probability is 0.5 then the output is 1.
But without an activation function, y value has no bound. For that, you have to use an activation function and wrap up the value within a certain bound. Only then a neuron can learn whether to fire this output or not.
Types of Activation functions
- Linear
- Non-Linear
Linear Functions
It is the simplest function that translates the input to the output. Almost no neural network uses linear functions in both hidden and output layers. With linear activation function, the neural network is calculating linear combinations of values. Because the range is from [-infinity, +infinity].

The derivative function can be given by
Non-Linear Functions
The non-linearity of the activation functions will allow you to “bend” your decision boundaries, which gives the models the power to fit complex datasets. By having a linear activation function in a multi-layer network, you are just training the model to behave like a neural network. The model will learn the complex features only if it is non-linear in nature. There are numerous functions that we can use as activation functions. Let’s explore.
Sigmoid function
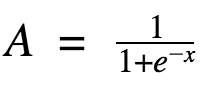
Sigmoid function can translate the input in range [-inf,+inf] to the range [0,1]. Sigmoid functions and their combinations generally work better in the case of classifiers. They are used for predicting probability-based output and has been applied successfully in binary classification problems, modeling logistic regression tasks as well as other neural network domains.
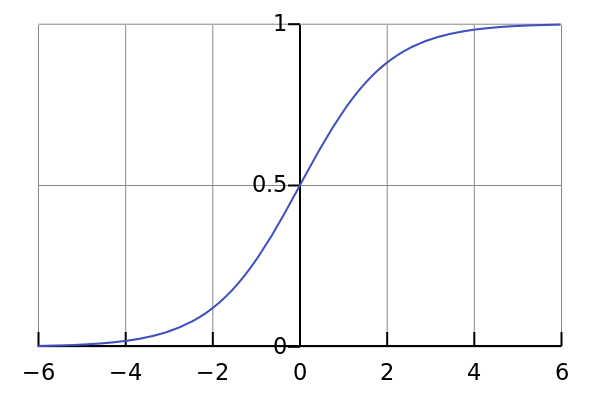
As you can see in the curve, the values are steep in the range [-2,2] , we can explain that a small change in X will have significant effect in Y. The function is continuously differentiable. So it can be used in backpropagation. Yet it posses vanishing gradient problems i.e, it is not a Zero centric function so it may cause dead neurons making them not fire at all. The network refuses to learn further or is drastically slow.
Tanh function
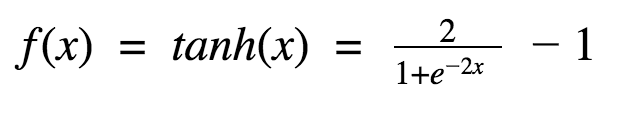
This is a scaled version of sigmoid function,
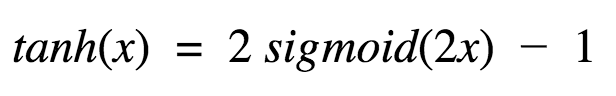
The tanh function is a smoother zero-centered function whose range lies between -1 to 1.The tanh function became the preferred function compared to the sigmoid function in that it gives better training performance for multi-layer neural networks. However, the tanh function could not solve the vanishing gradient problem suffered by the sigmoid functions as well. The main advantage provided by the function is that it produces zero centered output thereby aiding the back-propagation process.
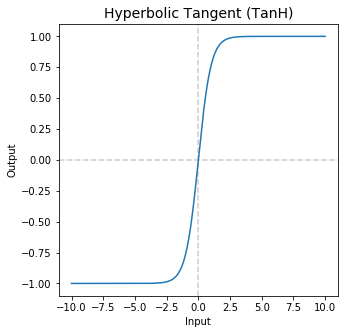
They have been used mostly in recurrent neural networks for natural language processing and speech recognition tasks.
Softmax function
This is another type of activation function used to compute the probability distribution from a vector of values. The Softmax function produces an output which is a range of values between 0 and 1, with the sum of the probabilities equal to 1.

This function is mostly used in multi-class models where it outputs the probability for all classes with the target class of high probability. It appears mostly in output layers in most of the architectures.
The main difference between softmax and sigmoid is that sigmoid function is used in binary classifiers whereas softmax function is used in multivariate classifiers.
ReLu function
The ReLU activation function performs a threshold operation to each input element where values less than zero are set to zero thus the ReLU is given by

This function rectifies the values lesser than zero and eliminating the vanishing gradient problems. So it will be used in hidden layers and another activation function will be used in the output layer.
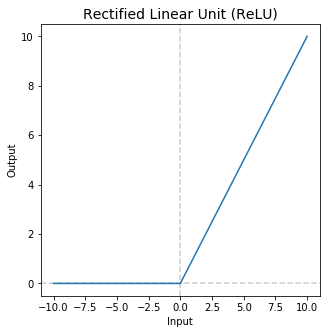
The main advantage of ReLu is the computation power is faster since it does not calculate exponents and divisions. It can squish values between 0 to maximum. The backpropagation is possible. Not all the neurons are activated at the same time eliminating the negative inputs. The gradient is zero for negative inputs leads to dead neurons. The weights are not updated during backpropagation because of dead neurons.
Leaky ReLu
This is an improved version of ReLu function. The function is given by

For the inputs less than zero, we can multiply by a very small value.
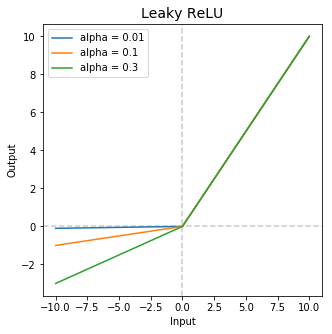
The main advantage of replacing the horizontal line is to remove zero gradients. The gradients to the left side are non-zero thereby making no dead neurons.
df/dx=1 , x≥0
df/dx=0.01 . x<0

The Leaky ReLu has an identical result compared to ReLu function with the exception that it has non-zero gradients over the entire duration thereby suggesting that there is no significant result improvement except in sparsity and dispersion when compared to the standard ReLU and tanh functions.
Parametric Rectified Linear Units (PReLU)
The PReLu is another variant of ReLu function and it has the negative part of the function being adaptively learned while the positive part is linear.

It can be rewritten in a compact format:
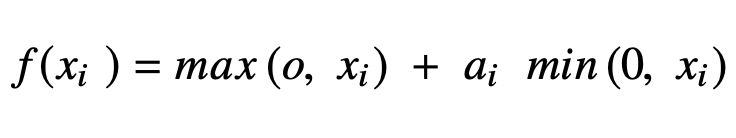
The authors reported that the performance of PReLU was better than ReLU in large-scale image recognition and these results from the PReLU were the first to surpass human-level performance on visual recognition challenges. And all the variants of ReLu outperform the ReLu power.
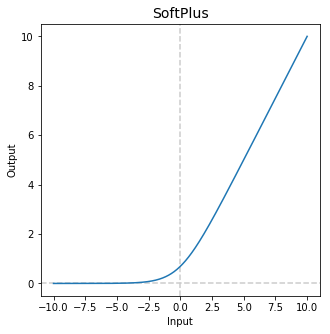
Softplus Function
It is a smooth version of the ReLU function which has smoothing and nonzero gradient properties, thereby enhancing the stabilization and performance of deep neural network designed with softplus unit. The Softplus function is a primitive of the sigmoid function, given by the relationship
f (x) = log(1 + eˣ )
The comparison of Softplus with sigmoid and ReLu results in an improved performance with lesser epochs to convergence during training, using the Softplus function.
Exponential Linear Units (ELUs)
This is a less widely used variant of ReLu. It follows the same rule when x≥0 but it is increasing exponentially for x<0.
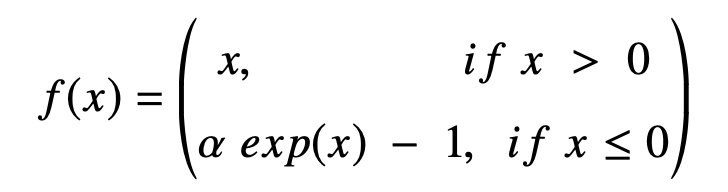
It has only one parameter α which controls the scale of the negative part, and by default is set to 1.0.
The main advantage of the ELUs is that they have negative values which allow for pushing of mean unit activation closer to zero thereby reducing computational complexity thereby improving learning speed. They can offer faster training and better generalizations than ReLu.
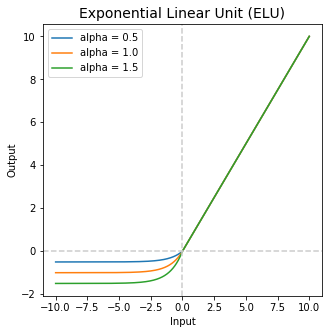
Scaled Exponential Linear Units (SELU)
The SELU was introduced as a self-normalizing neural network that has a peculiar property of inducing self-normalizing properties. It has a close to zero mean and unit variance that converges towards zero mean and unit variance when propagated through multiple layers during network training, thereby making it suitable for deep learning application, and with strong regularisation, learns robust features efficiently. The SELU is given by

It extends ELU with parameter lambda, responsible for scaling both positive and negative parts. α and τ are hardcoded in this function are roughly equal to 1.67 and 1.05 respectively.
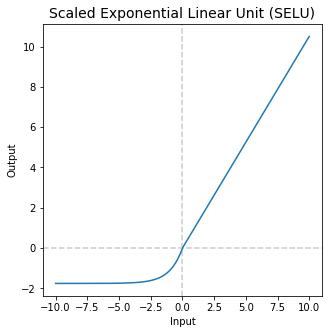
Maxout function
This WTx + b make up the pre-activation of the hidden unit. In traditional neural nets, this pre-activation is passed through a sigmoid activation to convert to -1 and 1. The maxout activation instead takes the maximum value of the pre-activations and reshapes it into a vector containing only this value.
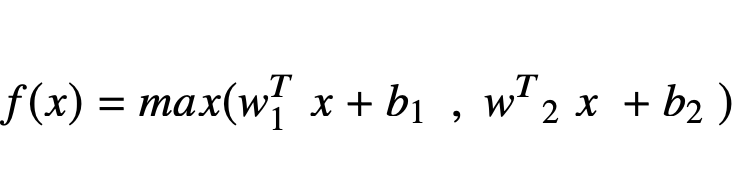
The Maxout AF is a function where non-linearity is applied as a dot product between the weights of a neural network and data. The Maxout generalizes the leaky ReLU and ReLU where the neuron inherits the properties of ReLU and leaky ReLU where no dying neurons or saturation exist in the network computation.
The major drawback of the Maxout function is that it is computationally expensive as it doubles the parameters used in all neurons thereby increasing the number of parameters to compute by the network.
Summary
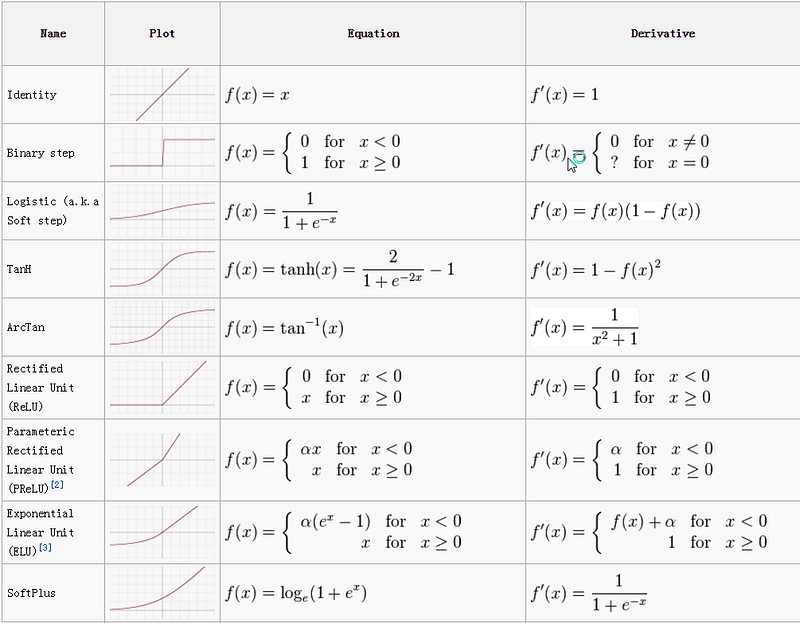
Conclusion
This is all about the most widely used activation functions. Choose the best activation function for your network so that the convergence of a model takes place at a faster rate. Thereby reduces the training time. Try different activation functions and you will definitely come to know what types of functions can be used for the different problems.
Comments
Post a Comment