GPT-3 model and Few-shot Learning — All you need to know
Need to create a machine translation model to translate Spanish to English? Need to create a model for personal assistants like Siri or Google Assistant? Need to create a model for natural language generation? It is not possible without a large amount of task-specific data for each task.
The most important in any deep-learning task is the requirement of a large set of training data. GPT-3 eliminates the step of the gathering of a large set of data. Just a limited amount of task-specific data and a pre-trained model can be used to generate any kind of model mentioned above.

GPT-3 model
- GPT-3 model is an auto-regressive model that is trained to produce human-like behavior. GPT refers to “generative pre-trained transformer” — an unsupervised deep learning algorithm that is usually pre-trained on a large amount of unlabeled text. It has a bigger Architecture with up to 175 Billion parameters.
- A statistical model is said to be auto-regressive if it predicts future values based on past values. (Ex- Sequence to sequence modeling)
- A model that develops a broad set of skills & pattern recognition abilities at training time.
- It then uses those abilities at inference time (task-specific training to rapidly adapt to or recognize the desired task.
- Let us consider an example, a child would have no problem recognizing a zebra if it has seen a horse before and read somewhere that a zebra looks similar to a horse, but has black-and-white stripes.
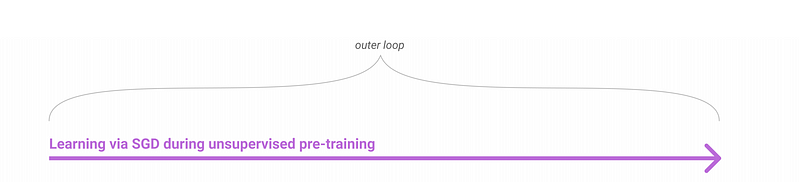
Using the large training data-set, the model is pre-trained with up to 175 billion parameters that learn a broad set of skills. This is also known as meta-learning.
The end result of this meta-learning is a model that can reach high performance on a new task with as little as a single step of regular gradient descent (i.e, with only a smaller amount of data).
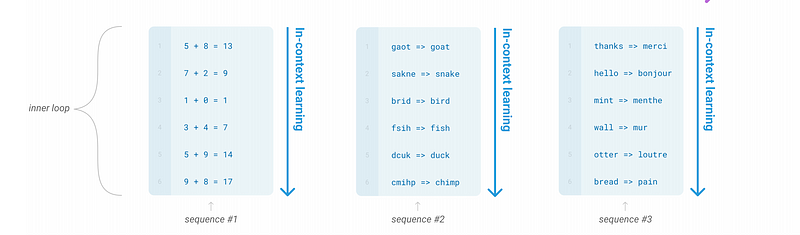
The pre-trained model can be used for different tasks such as Arithmetic operations, Machine Translation, etc., with the help of few-shot learning.
Zero-shot vs one-shot vs few-shot learning
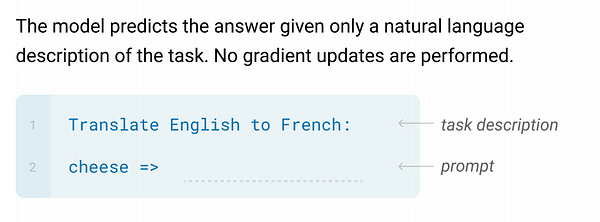
- Zero-shot learning: The pre-trained model will be used directly for another task without any task-specific example is given.

- One-shot learning: The pre-trained model will be used for another task with only one task-specific example K=1 from each output class.

- Few-shot learning: The pre-trained model will be used for another task with few task-specific examples (say 10<K<100) from each output class.
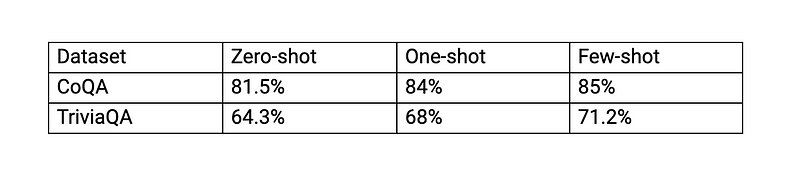
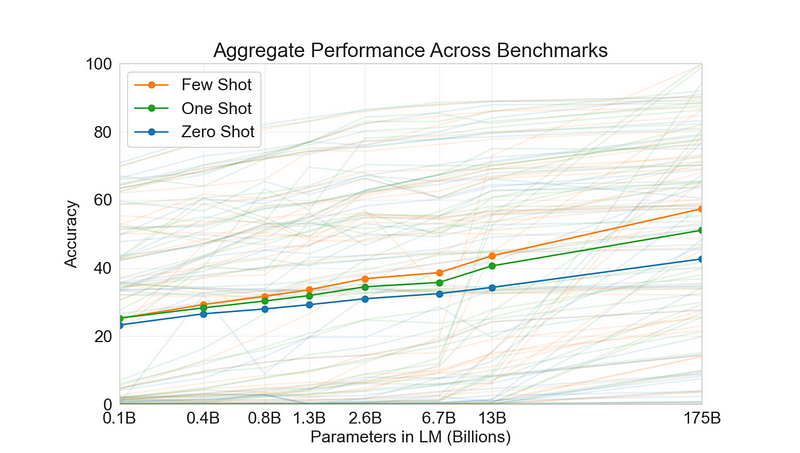
The accuracy is better in the order of few-shot learning > one-shot > zero-shot, yet the accuracy is not up to other state-of-the-art models.
Fine-tuning vs few-shot learning
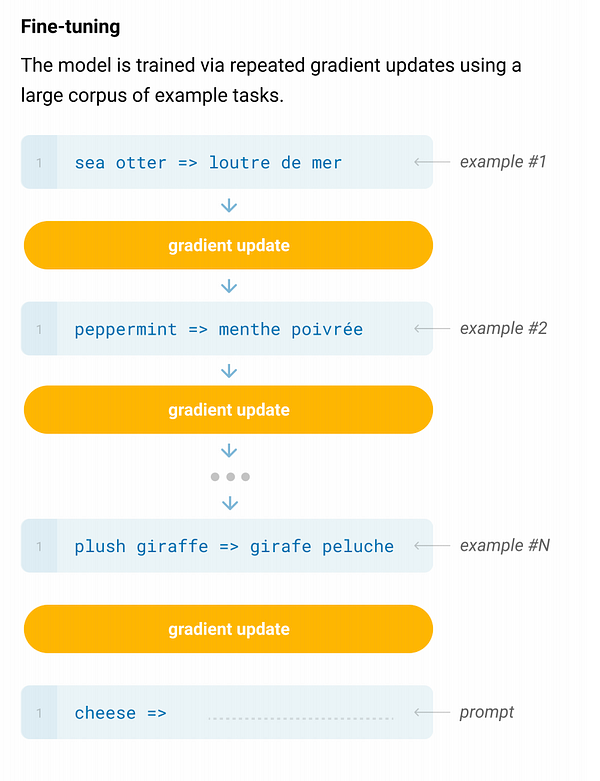
In fine-tuning, task-specific data is required and it is applied to the pre-trained model. During the training, weight updates happen which means the model is not generic, it needs a large amount of data for fine-tuning.
Whereas in GPT-3, you will not do weight updates yet few examples will be shown to the model. And only a small amount of samples from each output class are introduced to the model with the description to the model as text.
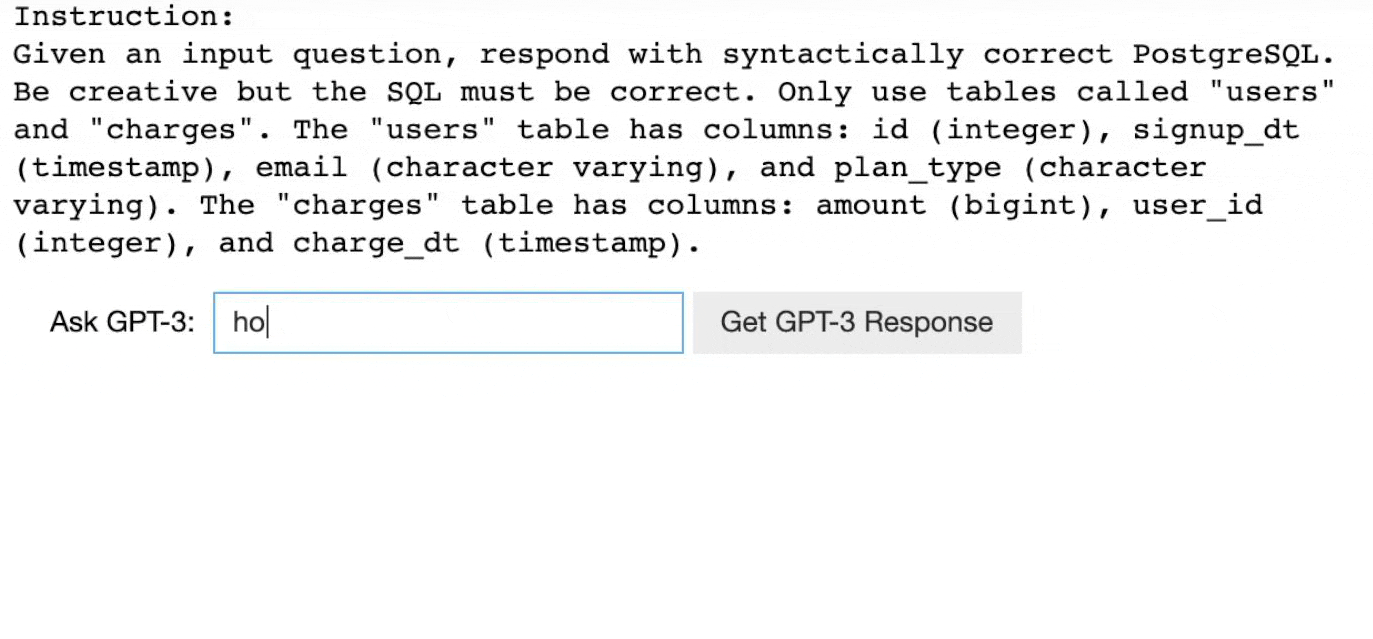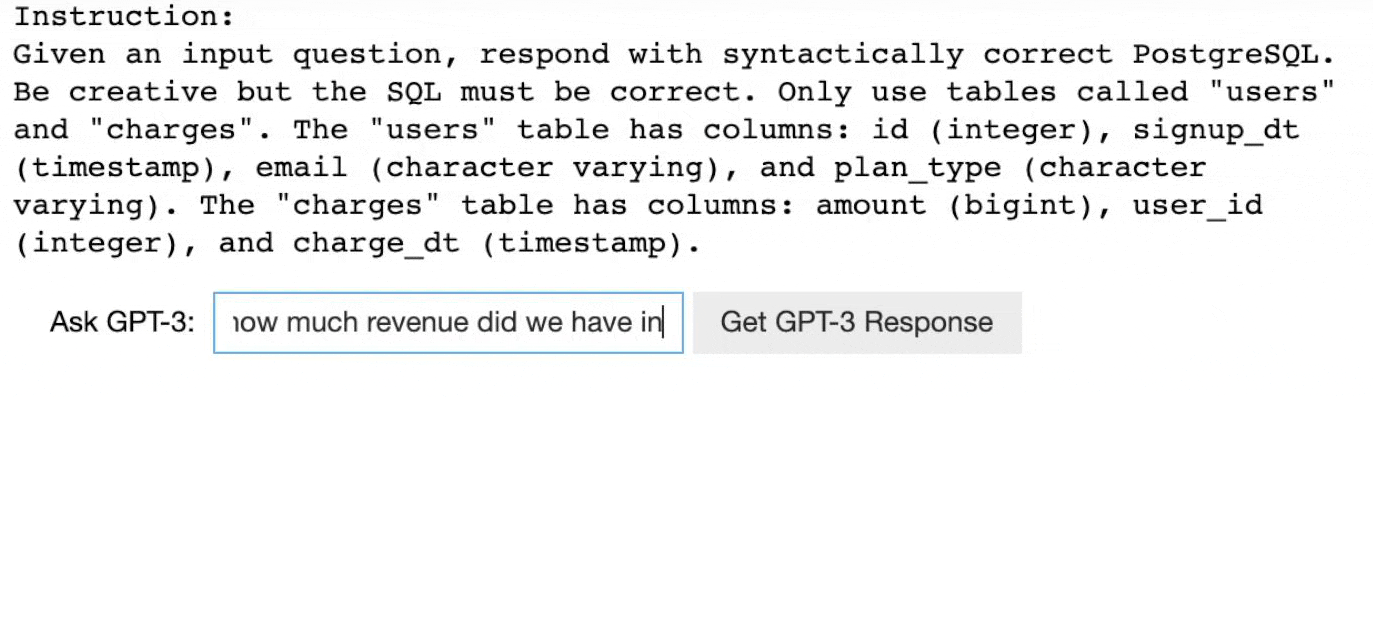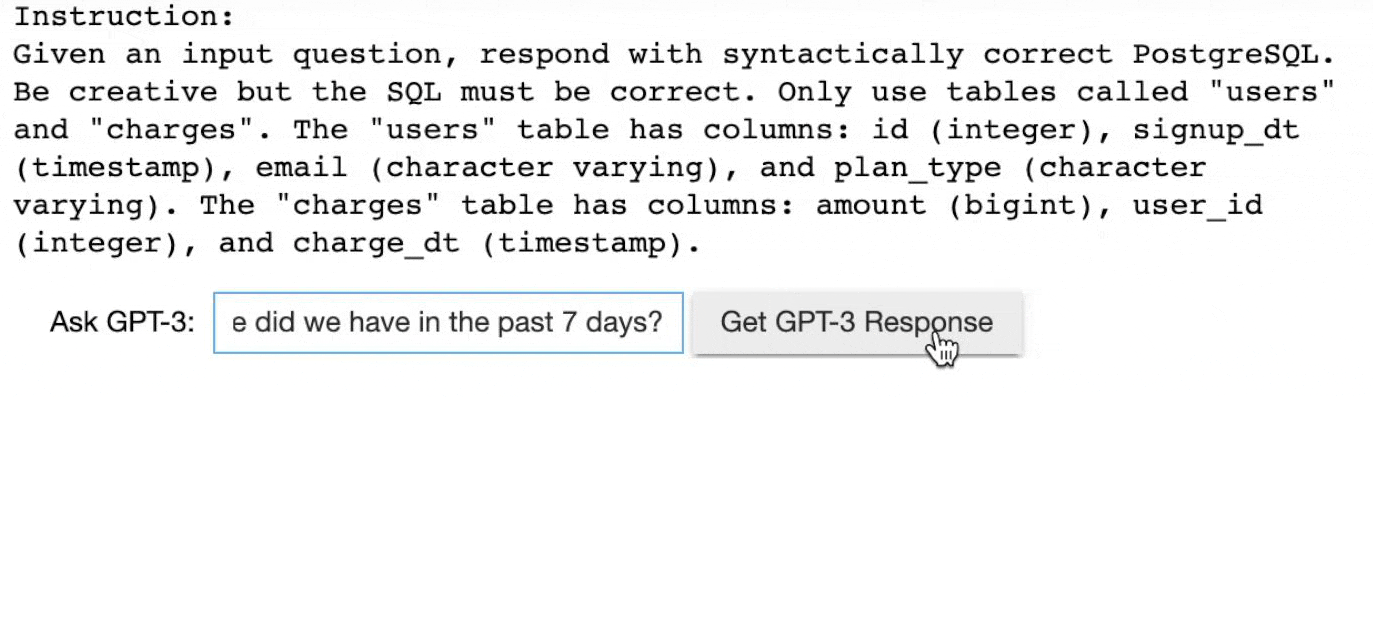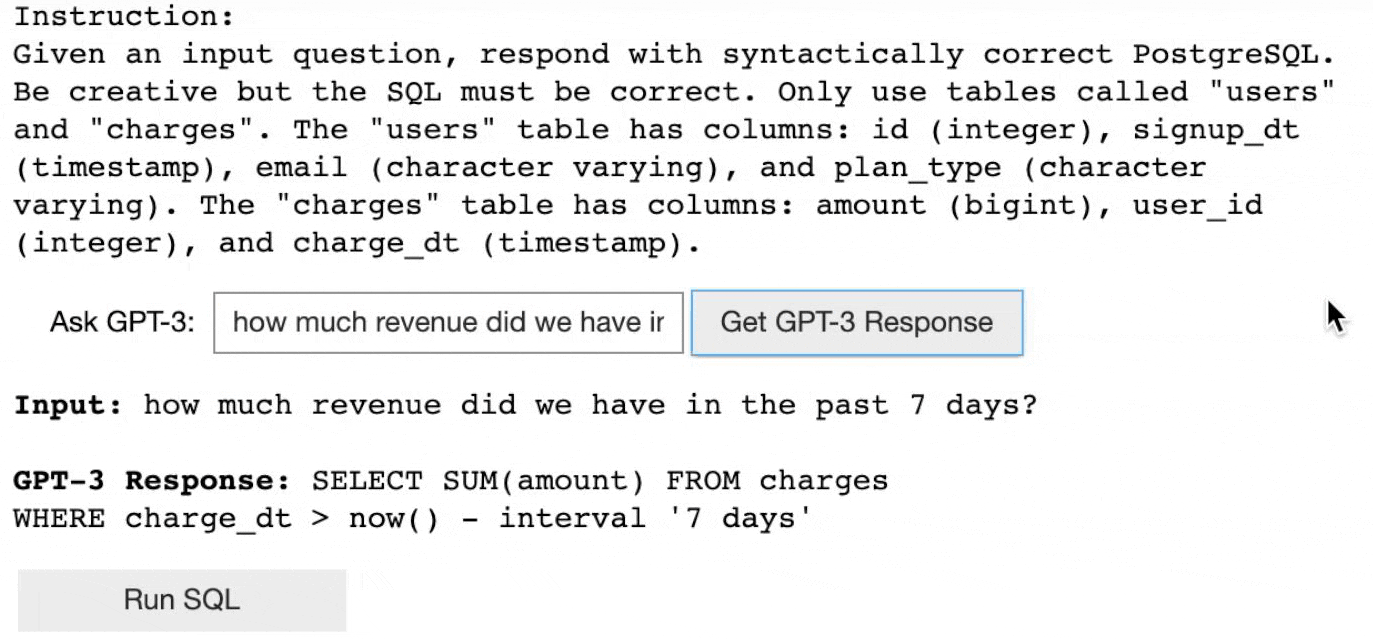
As you can see in the above demo of GPT-3, users can give only a description of the task and the model generates answers w.r.t each question. Consider it as you are explaining to your friend how to play football as simple instructions and he plays using your inputs. Remember the Child and Zebra example.
Approach to few-shot learning
The ability of an algorithm to perform few-shot learning is typically measured by its performance on n-shot, k-way tasks.
N stands for the number of classes, and K for the number of samples from each class to train on.
A model is given a query sample belonging to a new, previously unseen class. It is also given a support set, S, consisting of n examples each from k different unseen classes. The algorithm then has to determine which of the support set classes the query sample belongs to.
Attributes are given as input in k-shots (bird features: feather type, color as numeric input), and the model’s accuracy will be determined by the prediction of the support set. It has been proved that few-shot learning performs better than other categories.
Thank you.
References:
Comments
Post a Comment