Automatic Speech Recognition Systems in Deep Learning
Automatic Speech Recognition (ASR) is one of the important tasks in the Artificial intelligence field. This is not a new concept to anyone. We use Speech recognition in a daily basis. Go to google search and click on the microphone in the search bar, speak and get results. This is one way of communicating with the computer. It understands the words spoken by different users around the world with different accents. Yet the computer can able to understand the speech signals. You will learn the details in this blog. Let's discuss the process like always.

ASR Stages
- Phoneme Detection / Acoustic Modeling
- Pronunciation Modeling
- Language Modeling
Acoustic Modeling
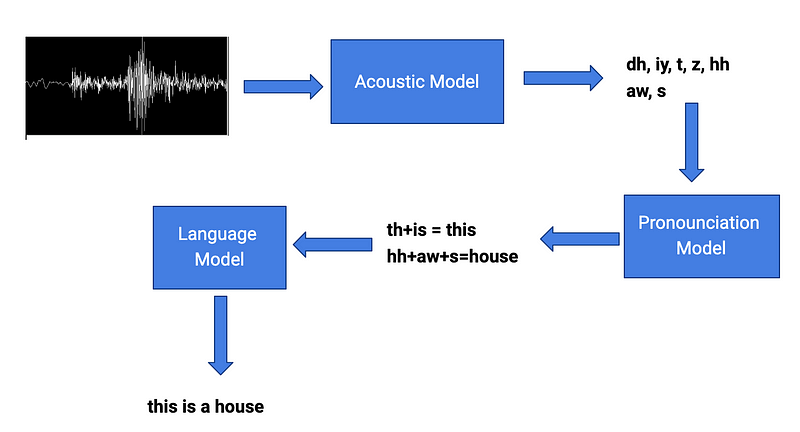
An acoustic model is used to represent the relationship between an audio signal and the phonemes or other linguistic units that make up speech.
We speak to the computer using a microphone. The microphone converts the sound signals into electrical signals. Then the sound card converts the obtained waveforms into digital signals (vector sequence). Now is the trickiest part, we use acoustic modeling to convert those vector sequence to phonemes. The phonemes are the sound units that distinguish one word from the other.
[HOUSE] = hh aw s
[HOUSEDEN] = hh aw s d ax n
Then, we use an acoustic model to establish a statistical representation(probability likelihood in Bayesian inference (p(y|x))) for the feature vector sequence computed from the waveform.
Pronunciation Modeling
A word pronunciation is a possible phoneme-like sequence that can appear in a real utterance and represents a possible acoustic pronunciation of the word. The common dictionary will be created using the words with the accurate phonemes connections called canonical pronunciation.
The pronunciation model can be used to map the phoneme-like units to the standard pronunciation that can be found in the common dictionary. These mapping the phoneme units to the correct pronunciation of the word are tougher than the other processes.
th+is = this
hh+aw+s = house
The problem comes with the different amount of speakers around the world with the different variations of pronunciations (phonemes).
Language Modeling
Language modeling is central to many important natural language processing tasks. The model learns about the probability distributions of a sentence over the sequences of words i.e, the likelihood of different phrases in a sentence.
P(w) = P (w1,w2,w3,…,wn)
Example:
P(“he is a boy”)= P(he) * P(is|he) * P(a|he is)* P(boy|he is a)
It provides the context to distinguish between words and phrases that sound similar.
“recognize speech” , “wreck a nice beach”
Consider the above phrases, they sound similar but mean different things.
Points to note:
- The above traditional models: Acoustic Model, Pronunciation Model, and Language Model are separately trained with different objectives.
- This is a traditional approach. But we are living in a world of deep learning.
- We can train a single model for this whole approach. That's what researchers did and the current state-of-the-art model in speech recognition is the deep learning model.
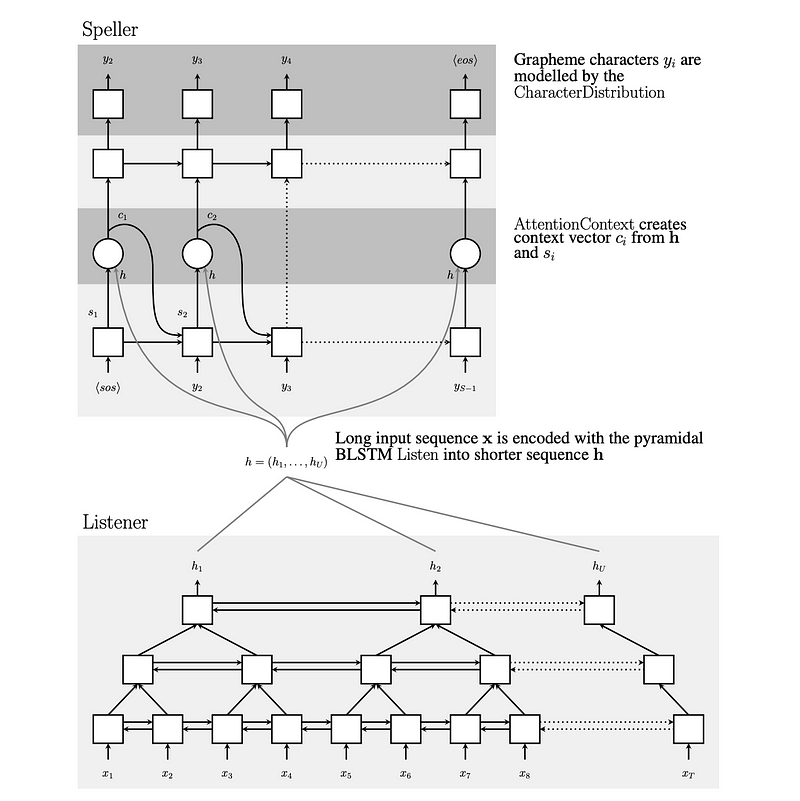
Listen, Attend, Spell (LAS)
In this architecture, we use the Encoder Recurrent neural network and decoder RNN with the attention mechanism.
For a deep understanding of Encode-Decoder architecture and its working, I recommend you to read my another blog carefully,
Understand about the advanced concept of Deep Learningmedium.com
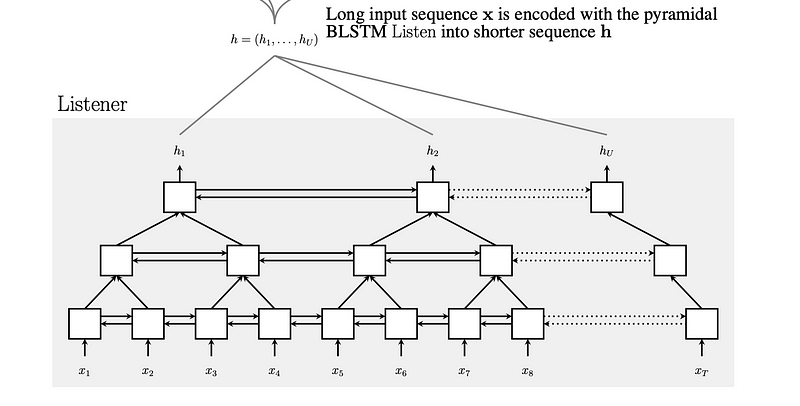
The Encoder (Listener) converts speech signals to high-level features i.e, converting the acoustic signals into a single-dimensional vector (hidden vector). The Decoder (Speller) used to convert high-level features into output text using the attention mechanism.
Listen
In the encoder part, the input(x) can be hundreds to thousands of frames long. So the RNN LSTM is replaced with Bidirectional LSTM (BLSTM)with the pyramid structure instead of stacked layers. This modification is required to reduce the length of the inputs to the subsequent layers.
The outputs of successive BLSTM cells of each layer are concatenated at each timestep and will be given as input to the next layer. At each layer, the time resolution reduced by the factor of 2. By reducing the time resolution, the attention mechanism can extract relevant information from the inputs. The encoded hidden vector will be computed at the end of the encoder stage.
Attend and Spell
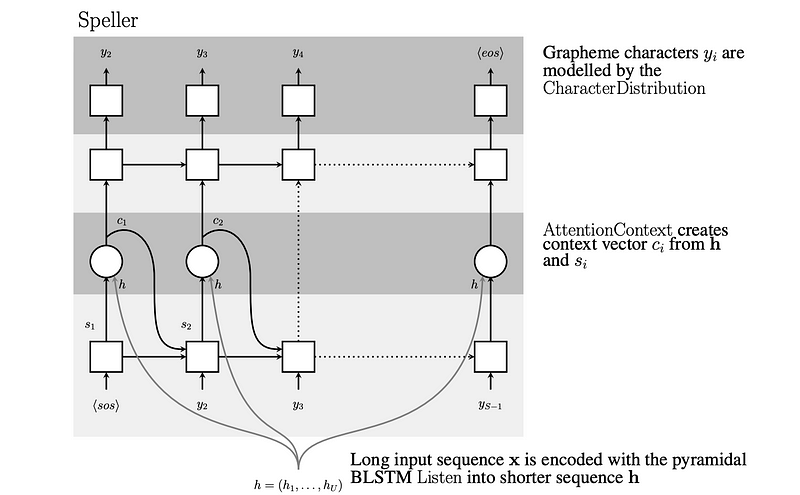
The hidden vector will be used as the input to the decoder (speller). The decoder LSTM will produce the output at each step by calculating the likelihood probability for the next character considering the previous words. Neural Network needs to compress all the information of the source sentence into a fixed vector length. It can be tricky during the testing time that is is difficult for NN to cope with a longer duration of acoustic signals.
The attention mechanism updates the hidden context vector at each output step by encapsulating the required information for the next states. At each step, it ranks all the outputs by relevancy using the beam search. The word with the highest score will be considered as the word to be focused on the current step.
Summary
Encoder-Decoder models are jointly trained to maximize the conditional probabilities of the target words given the input signals.
References
- https://arxiv.org/pdf/1508.01211.pdf
- https://www.isca-speech.org/archive/Interspeech_2017/pdfs/0233.PDF
- http://verbyx.com/blog/2019/11/28/what-is-an-acoustic-model-and-why-you-should-care/
Gracias!
Comments
Post a Comment