Understanding Encoder-Decoder Sequence to Sequence Architecture in Deep Learning

In deep learning, many problems can be resolved by constructing the better architecture. The RNN and its variants are very helpful in sequence to sequence learning. The RNN variant LSTM (Long Short-term Memory) is the most used cell in seq-seq learning tasks. The model takes an input sequence and outputs a sequence as output (i.e., many-to-many) is known as the sequence to sequence tasks. The sequence to sequence tasks are very challenging as the size of the inputs and outputs vary.
To tackle many-to-many sequence prediction problems, researchers have explored and find a way in the form of Encoder-Decoder Architecture. In this blog, we will learn about the Encoder-Decoder model.
Encoder-Decoder Model
There are three main blocks in the encoder-decoder model,
- Encoder
- Hidden Vector
- Decoder
The Encoder will convert the input sequence into a single dimensional vector (hidden vector). The decoder will convert the hidden vector into the output sequence.
Encoder-Decoder models are jointly trained to maximize the conditional probabilities of the target sequence given the input sequence.
Example: English to Spanish Translation
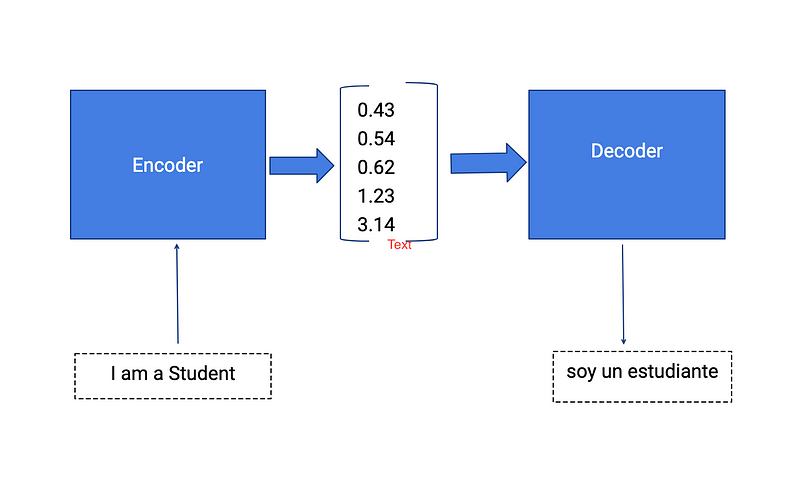
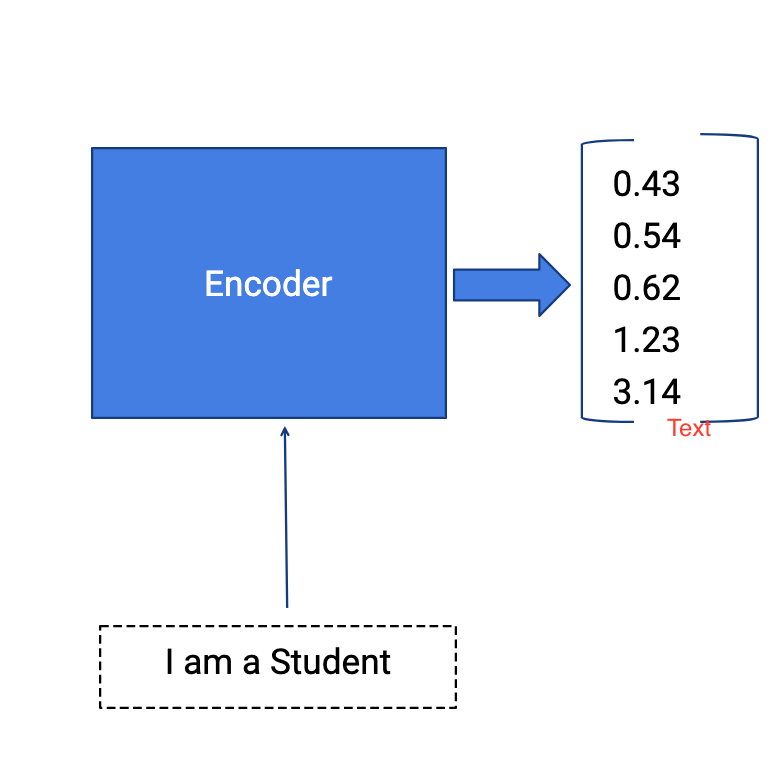
Encoder
- Multiple RNN cells can be stacked together to form the encoder. RNN reads each inputs sequentially.
- For every timestep (each input) t, the hidden state (hidden vector) h is updated according to the input at that timestep X[i].
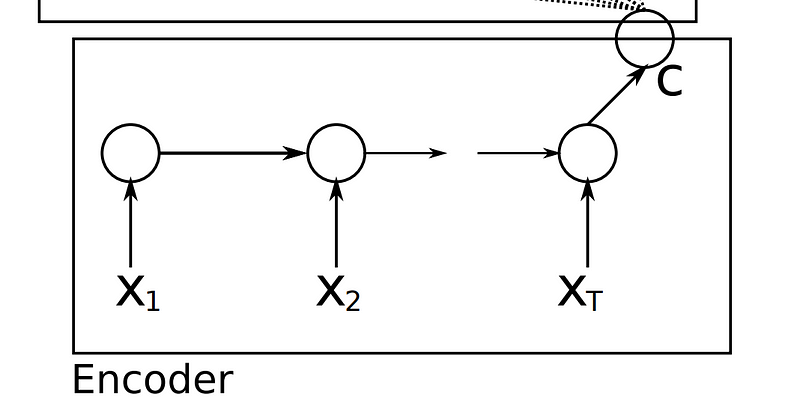
- After all the inputs are read by encoder model, the final hidden state of the model represents the context/summary of the whole input sequence.
- Example: Consider the input sequence “I am a Student” to be encoded. There will be totally 4 timesteps ( 4 tokens) for the Encoder model. At each time step, the hidden state h will be updated using the previous hidden state and the current input.
- At the first timestep t1, the previous hidden state h0 will be considered as zero or randomly chosen. So the first RNN cell will update the current hidden state with the first input and h0. Each layer outputs two things — updated hidden state and the output for each stage. The outputs at each stage are rejected and only the hidden states will be propagated to the next layer.
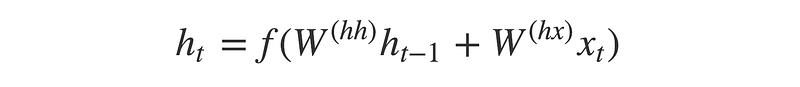
- At second timestep t2, the hidden state h1 and the second input X[2] will be given as input , and the hidden state h2 will be updated according to both inputs. Then the hidden state h1 will be updated with the new input and will produce the hidden state h2. This happens for all the four stages wrt example taken.
Decoder
- The Decoder generates the output sequence by predicting the next output Yt given the hidden state ht.
- The input for the decoder is the final hidden vector obtained at the end of encoder model.
- Each layer will have three inputs, hidden vector from previous layer ht-1 and the previous layer output yt-1, original hidden vector h.
- At the first layer, the output vector of encoder and the random symbol START, empty hidden state ht-1 will be given as input, the outputs obtained will be y1 and updated hidden state h1 (the information of the output will be subtracted from the hidden vector).
- The second layer will have the updated hidden state h1 and the previous output y1 and original hidden vector h as current inputs, produces the hidden vector h2 and output y2.
- The outputs occurred at each timestep of decoder is the actual output. The model will predict the output until the END symbol occurs.

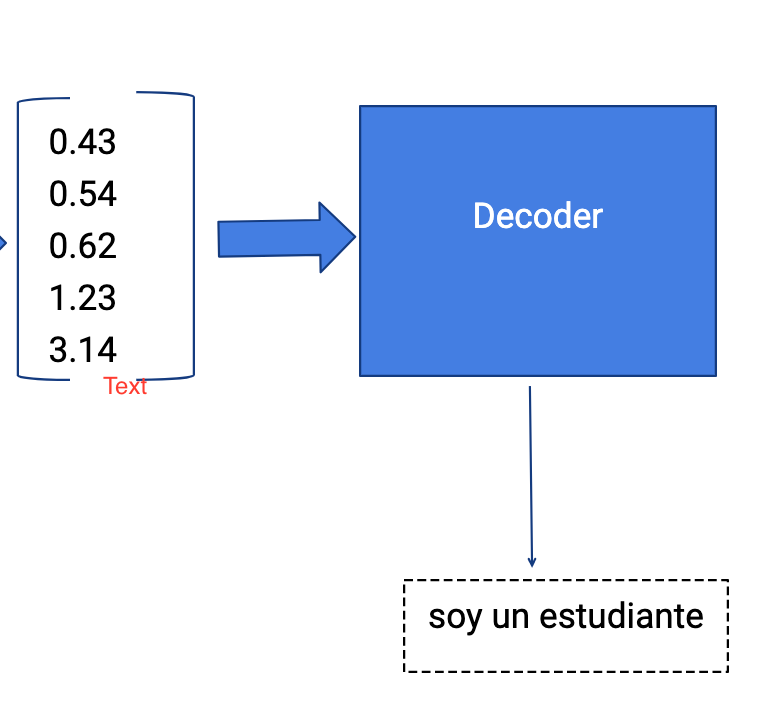
Output Layer
- We use Softmax activation function at the output layer.
- It is used to produce the probability distribution from a vector of values with the target class of high probability.
For more info about Activation functions, refer
Applications
It possesses many applications such as
- Google’s Machine Translation
- Question answering chatbots
- Speech recognition
- Time Series Application etc.,
Cons of Encoder-Decoder Architecture:
Con 1:
The above architecture represents the basic seq-seq model and thus they cannot be used for complex applications. The single hidden vector cannot encapsulate all the information from a sequence.
Solution: Reversing the Sequence
- RNNs learns much better when the input sequences are reversed.
- When you concatenate the source and target sequence, you can see that the words in the source sentence are far from the corresponding words in the target sentence.
- By reversing the source sentence, the average distance between the word in source sentence and the corresponding word in target sentence are unchanged but the first few words are now very close to each other in both source and target.
- This can be helpful in establishing a proper back propagation.
Con 2 :
Neural Network needs to compress all the information of the source sentence into fixed vector length. It can be tricky during the testing time that is is difficult for NN to cope with longer sentences especially those are not in the corpus. The performance of Encoder- Decoder decreases with the increase in length of the sentences.
Solution: Using Attention Mechanism
- In this model, there occurs the chances of missing the importance of a word. NN cannot able to focus on the important word. It can be solved using Attention mechanism.
- The Attention mechanism stores the output of the previous RNNs.
- At each step, it ranks all the outputs by relevancy.
- The word with the highest score will be considered as the word to be focused on the current step.
For more info, refer Jointly learning to Align and translate paper.
https://arxiv.org/pdf/1409.0473.pdf
Con 3:
While creating hidden vectors for longer sentences, the model doesn’t address the complexity of the grammar. Example: While predicting the output for the nth word, it considers only the 1st n-words in a sequence before the current word. But grammatically, the meaning of the word depends on words present before and after the current words in a sequence.
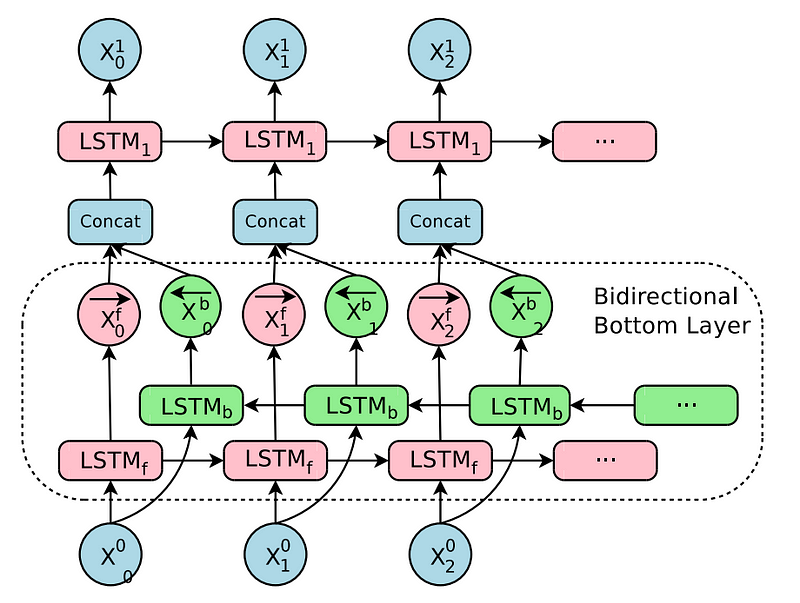
Solution: Bi-directional LSTM
- It allows to input the context of both past and future words to create encoded context vector i.e output of the encoder.
- At the first layer, the inputs will be given as left-to-right and at the second layer, the inputs will be given as right-to-left.
- The outputs from the both layers are concatenated and given as input to the third layer.
Con 4:
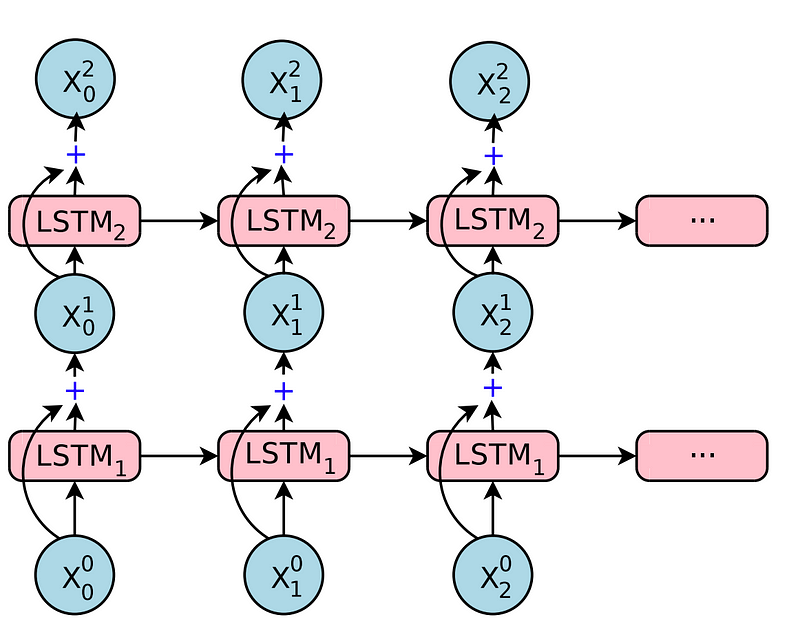
Simply stacking the number of LSTM layers will work only to a certain amount of layers, beyond that the network result in decreased efficiency and slow training time.
Solution: Adding Residual Connections
This can be solved using residual connections. The input of the current layer will be element-wise added with the output of the current layer. The added output will be given as the input to the next layer. These residual connections will make the memory states more efficient.
References:
- https://arxiv.org/pdf/1406.1078.pdf
- https://arxiv.org/pdf/1609.08144.pdf
- https://arxiv.org/pdf/1409.0473.pdf
- https://machinelearningmastery.com/encoder-decoder-long-short-term-memory-networks/
Bonus Information:
If you want to make training time faster, you need to use GPU instead of CPU. Check out the reason here,
This article is about GPU and its importance in the field of Deep Learning. Many state-of-the-art Deep learning…medium.com
Gracias!
Comments
Post a Comment