Neural Architecture Search (NAS) — AutoML Process

Introduction
In the world of artificial intelligence, everyone is immersed in the field of deep learning. Day by day, deep learning takes place in the position of every machine learning models. The capacity of learning like a human brain made it the best fit to be used in the field of artificial intelligence.
The last few years have seen much success of deep neural networks in many challenging applications such as speech recognition, computer vision, image recognition, machine translation etc., Along this success there is also a problem of designing the best architecture and features for the network. The designing procedure still requires a lot of experts of knowledge.
To tackle this problem, A group of researchers in Google Brain team have created a deep neural network which will decide the best architecture for the given dataset.
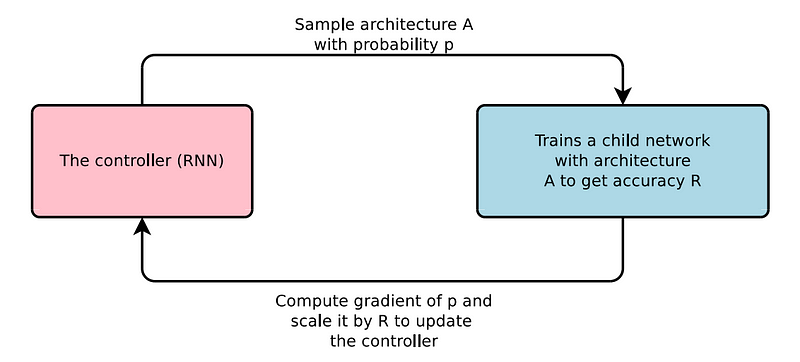
It is possible to represent the structure and connectivity of a neural network such as the number of layers, activation functions and output activation functions in a variable length string.
[“layers=5”,”activation_function=relu”,”output_activation=softmax”]
So, it is possible to use a recurrent network as the controller to generate such string.

The controller in Neural Architecture Search is auto-regressive, which means it predicts one hyper-parameters at a time conditioned on previous predictions.
RNN controller
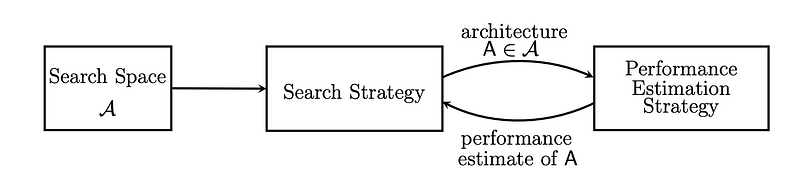
Search Space:
The input to the RNN controller will be the variable length string like
[“layers=[1,3,5,7]”, “activation_function=[sigmoid,tanh,relu]”,”output_activation=[softmax]”]
Search Strategy:
The controller will generate the possible configurations from the given input with some probability. The network uses reinforcement learning to learn over time. Taking those inputs, the RNN controller generates an output such as
[“layers=3”,”activation_function=tanh”,”output_activation=softmax”]
The child network is created using these configurations, and it is trained on the training dataset. The accuracy of the child network is noted and sent as a reward signal to update the controller. The objective here is to maximize the expected accuracy of the child model. Here, the reward signal is a scalar value. So The Policy gradient method is used to update the controller. Using these, the controller learns to generate the best architectures over time.
Weight Update Using Policy Gradient Method
Let's learn something about the policy gradient method before going to updation in RNN controller.
Policy Gradient Network:
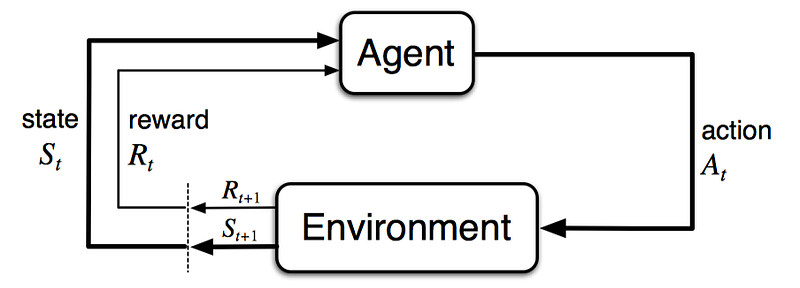
The reward hypothesis states that all the goals and purposes of an agent can be explained by a single scalar called the “reward”.
The agent must follow a framework such as a Markov Decision process which consists of a decision to be made at each state. This gives rise to a sequence of states, actions, and rewards known as “trajectory”.
The objective of the policy gradient network is to maximize the set of rewards.
Markov Decision Process:
It is a tuple (S,A,R,p,γ) such that it predicts what decision to be made at each step.
S-State Space
A-Action space
R-Reward space
p-dynamics of the process
Generally p the dynamics of the environment are outside the control of an agent.
Imagine standing in the windy environment(environment) , you try to take each step (action) in four directions at each second (state). The directions are perfectly aligned in North, south, West and East. This probability of landing in a new state at the nest second is given by the dynamics p of the windy field. It is certainly not in agents control.
But what if you somehow understand the dynamics of the environment and move in a direction different from North, South, West and East. This policy is what agent controls.
When an agent follows a policy P, it generates the sequence of states , actions, and rewards called the trajectory.
The policy is defined as the probability distributions of the actions given a state.
P(At=a, St=s)
Where At ∈ A , St ∈ S
The main objective of the algorithm is to maximize the expected reward when following a policy P.
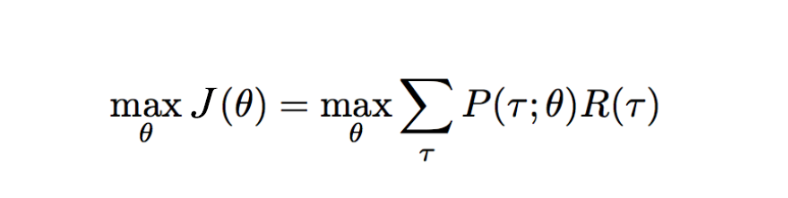
The Gradient Ascent Method is used here to solve the maximization problem.
Using Policy Gradient in RNN controller
The list of tokens generated by the RNN controller are considered as actions A. At convergence, the child network will achieve the accuracy R on the test dataset. The accuracy R is used as the reward signal and use reinforcement learning to train the controller. The objective to maximize the expected accuracy θ is given by
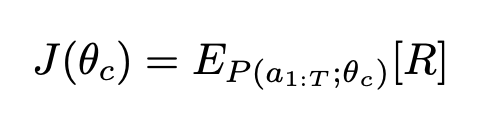
The reward R here is the non-differentiable scalar value. So apply policy gradient method to update the θ. Here we use REINFORCE rule,
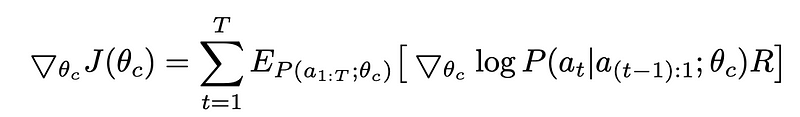
By considering the number of different architectures m and number of hyper-parameters T, an empirical approximation of the above equation is given by
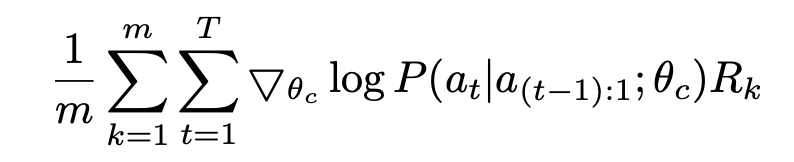
Consider this process as maximum likelihood estimation (MLE), no matter how bad the estimates are, in limit of a data, the model will converge to true parameters.
But with high variance, it is hard to stabilize the model parameters. We instead try to optimize the difference in reward by introducing baseline b.
To keep the gradient estimate unbiased, the baseline should be independent of policy parameters. The equation can be rewritten with baseline as
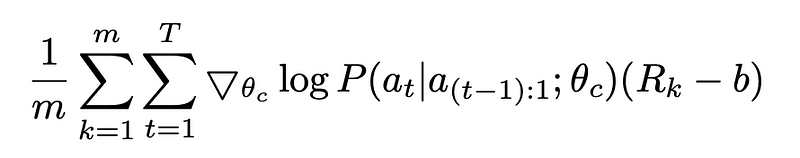
Here, the baseline b is an exponential moving average of previous architecture accuracies.
Parallel Training and Asynchronous updates
In this, each gradient update to controller parameters corresponds to training one child model work to convergence. We know that the model training takes hours; we use distributed training and asynchronous parameters updation to speed up the training process.
We have a parameter server S shards that controls the shared parameters of K controllers, which in turn trains m replicas of child networks. Using this way, we can speed up the training process to use different configurations for our dataset and can decide the best architectures which fits it.

If we set S=20, K=400 and m=1. Then 400 networks are being trained on 400 CPUs concurrently at any time. The asynchronous weight updates to the parameter-server happens once the 10 gradients from the replicas have been accumulated.
Experiment: Penn Treebank
Penn-Treebank is a well-known benchmark dataset for language modeling. Using Neural architecture search we will try to generate and create a better architecture of LSTM for language modeling.
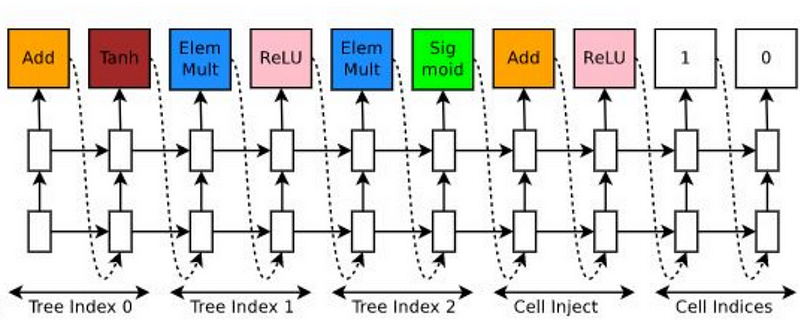
Our controller sequentially predicts a combination method and then an activation function for each node in a tree. The controller will generate the combination method from [add,elem_mul] and an activation function from [identity,tanh,sigmoid,relu].
The reward function is c/(validation perplexity)² where c is a constant set to 80.
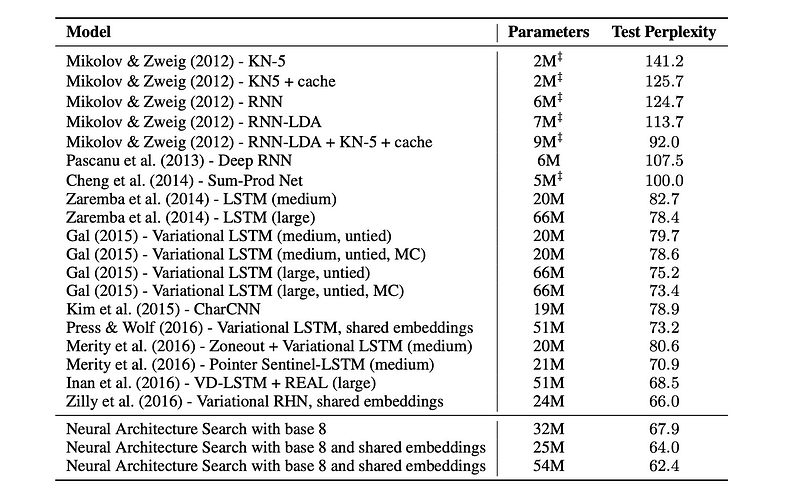
As can be seen from the table, the models found by Neural Architecture Search outperform other state-of-the-art models on this dataset, and one of our best models achieves a gain of almost 3.6 perplexity.
Identifying the optimizer
The optimizers are the updation algorithms that are used to change the weights of the network. There are different types of algorithms each have its own advantage such as Adam, RMS prop, Stochastic Gradient Descent(SGD) etc.,
Using the Neural Architecture Search we can also predict the best optimizer algorithm for the model. Adding another input to the controller will be enough to get the better architecture with optimizer.
Example:
Input:
“layers:[1,3,5,7]”,”activation_functions=[tanh,sigmoid,relu,leaky relu]”,”output_activation=[sotmax]”,”optimizer=[Adam,RMS Prop,SGD]”
Output:
“layers:5,”activation_functions=relu”,”output_activation=softmax”,”optimizer=Adam”
Conclusion
This article explained the future of deep learning. It automates the machine learning tasks. Using this method we can create the best architectures for all types of datasets. The RNN controller can generate variable length architectures and the architectures can be trained concurrently. The best architecture with the best accuracy can be chosen as the best model for the dataset.
References:
https://arxiv.org/pdf/1611.01578.pdf
https://arxiv.org/pdf/1808.05377.pdf
Thanks!
Comments
Post a Comment