Convolutional Neural Networks for Computer Vision Applications
This blog will help you understand the basics of CNN which is the base for most of the computer vision applications.

Why CNN?
The traditional neural network used for text classification and extraction uses the affine transformation of vectors with matrix multiplication. These architectures with complex connections have been producing state-of-the-art models. So why do we go for CNN?
The images that we see usually be stored in the computer in a matrix format. The images can be stored with different channels like grayscale, RGB, etc., The matrix of the image represents the pixels of the image in different channels. The value represents the intensity of the pixel for the corresponding color channel.
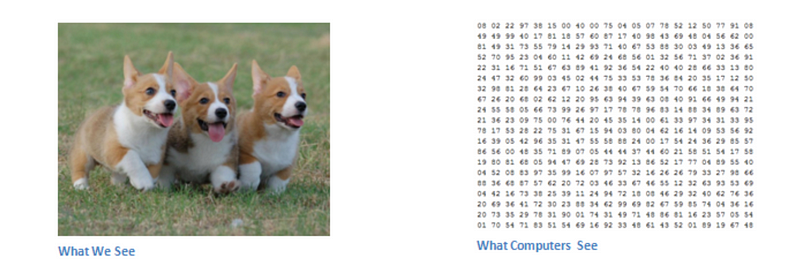
Consider you have an image with 480x480 pixels. So for RGB channels, 3x480x480 (6,91,200). If we follow the traditional neural network, we have to encode these values in the input layers. So 6,91,200 neurons in the first layer and it should be continued for the subsequent layers. The matrix calculations are more complex and are not scalable to a larger scale. That's why researchers have implemented a new way of handling the images.

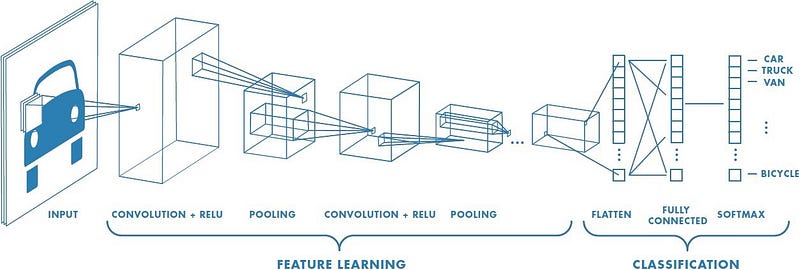
Stages in CNN
These are the stages in CNN that we will be looking into
- Input Matrix
- Convolutional Layer
- ReLu Activation
- Pooling
- Fully Connected Layers
- Output Classifier Layer
Convolutional Layer
The convolutional layer is used to determine the low-level features such as edges, color, gradient orientation, etc., using the filters. For the given image matrix, the convolutional layer will activate the pixel areas with respect to the filters. The filters are also called as kernels.
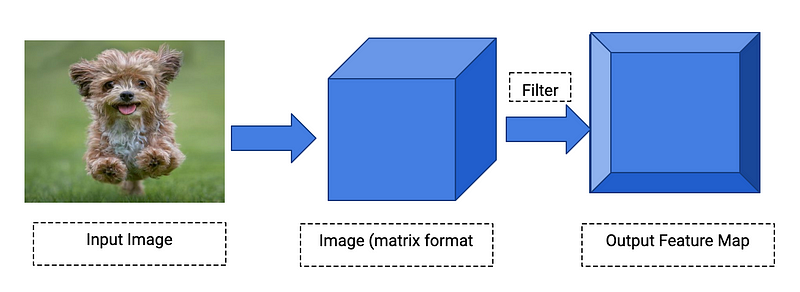
The filters will be in a matrix format with the depth as same as the input matrix depth(channel length). Example: You have an image, you have a curve detector filter, the filter will activate the curves in the image and the result will be in the output feature map.
- We can use many filters in the convolutional layer and should maintain all the output feature maps.
- The filters are hand-engineered. The filters such as straight-line detector, curve detector, color detector, etc., can be used in this layer.
- These primitive filters are used to capture the spatial and temporal dependencies of an image. The filters are the same as the weights of the traditional neural network.
- The aim is to reduce the image into a specific form without losing the features and it should be scalable to massive datasets.
This layer is also called a feature extraction layer.
Mathematical Part of the Convolutional layer
We need to know about strides and padding. We have an input matrix and filter matrix. We start the operation from the top right of the input matrix. Multiply the filter matrix with the first focused tile of the input matrix (element-wise multiplication). Add all the values and place them in the output feature matrix.
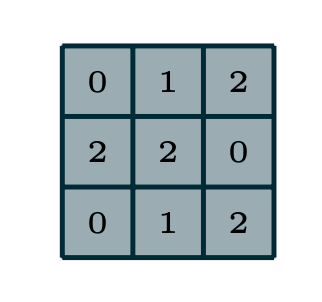
Now, we need to move the filter to all the areas of the input image to activate the pixels. The count of tiles moved is termed as Stride(N). If N=1, the filter will be moved tile by tile. Consider the filter on the left side, we can perform the convolution operation on the input image matrix.
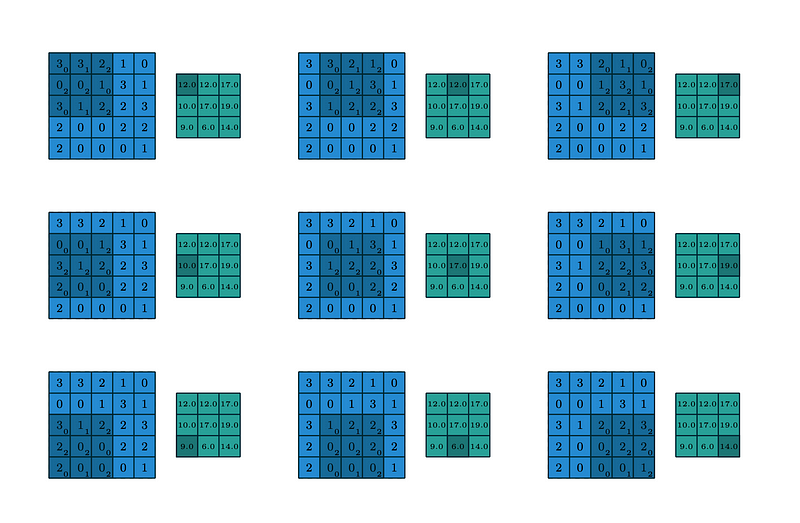
The above operation performs the element-wise multiplication of filter with the input image. As you can see, the filter moved by 1 tile on the whole input matrix. We considered stride N=1 here. After the multiplication, usually, bias will be added to the value.
For more info on the bias, consider reading this blog
Convolution Layer with Padding
Padding is the concept of appending zeros at the start and end of the input matrix.

In some cases, the information on the border of the image might get lost or less important. In order to bring in the features of the edges into the middle of the output feature map, we append zeros.
We can also adjust the stride size and the padding properties in the convolutional layer to cover all features of an image. On the whole model architecture, we can use stacked convolutional layers to identify the low-level features and high-level features on the subsequent layers. Thus consuming the most information from the image matrix.
ReLu Activation
The ReLU activation function performs a threshold operation to each input element where values less than zero are set to zero thus the ReLU is given by

So, if a given input matrix have positive and negative values, the relu activation function will filter all the negative values into zero.
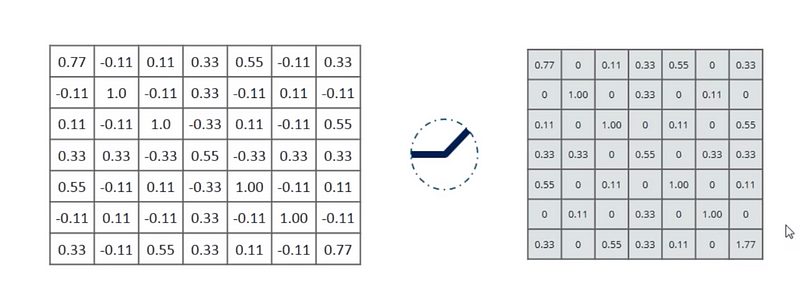
For more info on Activation Functions, refer this blog
Pooling Layer
The Pooling layer is used to reduce the dimensionality of the data. The pooling layer applies non-linear downsampling on activation maps. After applying the convolutional operation, the feature maps increases by large numbers for each filter. If the convolutional layers are stacked together, it might be more complex to perform training with backpropagation.
So the pooling layer is generally used to reduce the dimensionality of data. We can also consider this as a summary of the subregions with the help of the pooling function. The types of pooling are
- Max Pooling
- Average Pooling
Here, we need to consider the window and stride length to focus the specific content into the pooling function and the output value will be filled in the output matrix. Max Pooling extracts the maximum value of the focused tile and average pooling extracts the average value of the focused tile.
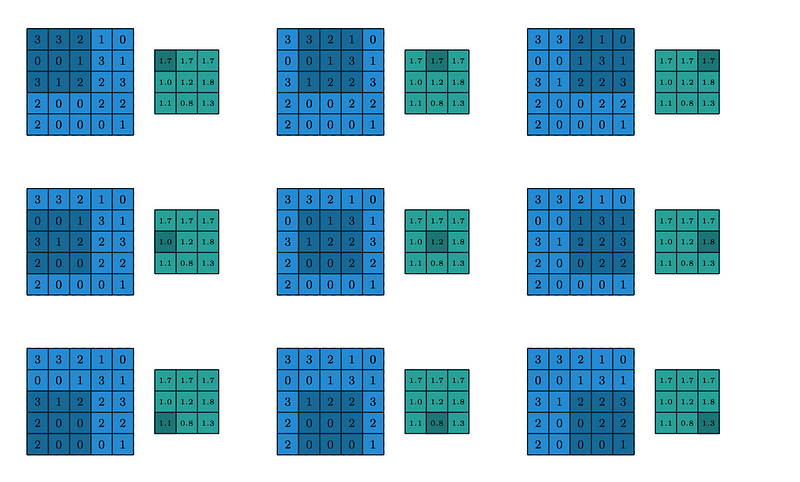
The above image represents the pooling window extracting the average value of the window with the stride N=1.
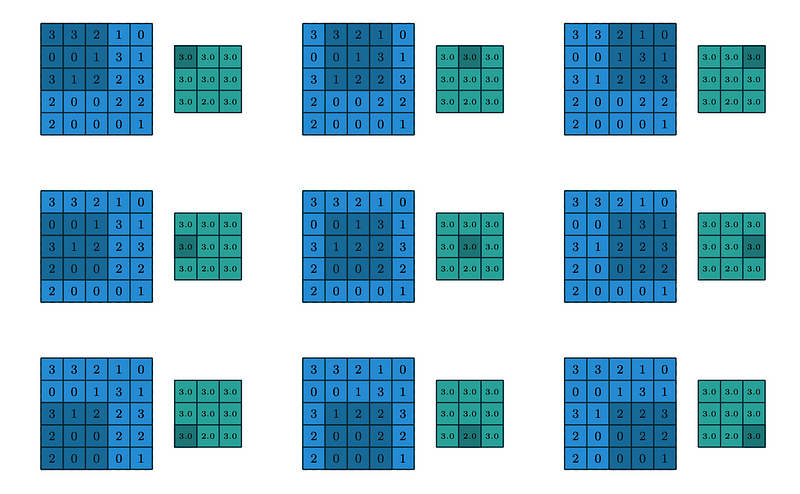
The above image represents the pooling window extracting the maximum value of the window with the stride N=1.
Fully Connected Layers
This is the final phase in the CNN architecture. Flattening the outputs. The result from the convolution/pooling layer will be converted into vectors. And here onwards, the normal neural network will consume this vector information to further use it for classification or encoding operations using RNN, etc., This layer will be used to learn the non-linear combinations of the high-level features.

This is similar to a traditional neural network with layers and its own weights and biases. Mostly softmax function is used in the output layer which best distribute the probability among the output classes. This function is mostly used in multi-class models where it outputs the probability for all classes with the target class of high probability.
References
- https://arxiv.org/pdf/1603.07285.pdf
- https://adeshpande3.github.io/adeshpande3.github.io/A-Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks/
- https://www.youtube.com/watch?v=umGJ30-15_A
- https://web.stanford.edu/class/cs231a/lectures/intro_cnn.pdf
- http://neuralnetworksanddeeplearning.com/
Gracias!
Comments
Post a Comment