Knowledge Distillation in Deep Learning
Dark Knowledge of Neural Networks
Introduction
This article is to understand how dark knowledge can be revealed from neural network. I would recommend you to have a basic knowledge about neural networks before looking into this article.
The genuine part of deep learning is that the neural network learns the value of parameters (weights and biases) to predict what can be the output for an input. The learning is an iterative process of forward propagation and backward propagation by the layers of neurons.
Knowledge Distillation
Although deep neural networks have harvested huge success in a variety of application domains, several researchers still have certain concerns with the poor interpretability of pure data-driven models. Hinton et al. took advantage of this end and first introduced the concept of knowledge distillation framework to transfer the knowledge from a large cumbersome model to a small model.
It is a technique of model compression in which a small model is trained to mimic a pre-trained large model. We build complex models to let the model learn the complex features. But At test time we want to minimize the amount of computation and the memory footprint. These constraints are generally much more severe at test time than during training. In the case of mobile applications, we cannot deploy cumbersome models because of the computation power required in mobile devices. So the experts have decided to invest the time in making the small model mimic the behavior of cumbersome model.
And another important thing is to retrieve the dark knowledge from the neural network. So we came to the part to know about what is dark knowledge?
Softmax function:
People use softmax as an activation function at the output layer for classification problems. The output will be the probability distributions for all the output classes and the sum of probabilities of all classes is equal to 1. The correct class output will have a high probability among all the outputs with all other class probabilities close to zero. It doesn’t provide much information beyond the ground truth provided in the dataset.
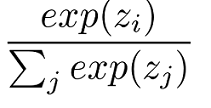
Example:
The model will look into the handwritten number ‘7’ and will output the number is 7 but it cannot say like number ‘1’ is much closer to number ‘7’.This is because the target output class will have a high probability and all other classes will have a probability closer to zero.
Softmax function with temperature:
The model that uses softmax with temperature as activation function at the output layer can output high probability for ‘1’ while predicting ‘7’ with high temperature.
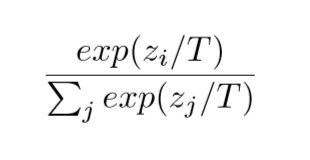
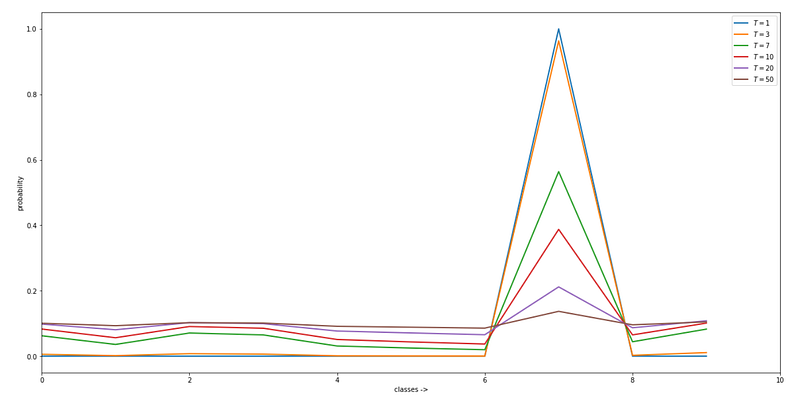
At each node, we divide the input by Temperature T . When T=1 we get the standard softmax function. As T grows, the probability distribution generated by the softmax function becomes softer providing more information as to which classes the model found more similar to the predicted class. This is called “dark knowledge” embedded in the model.
To extract this dark knowledge we used an ensemble of models in practice. So we turned it into knowledge distillation where a complex model (Teacher model) will be used to distill its knowledge to the small model (Student model) . The student model can be as complex as the teacher model or lesser. In practice, we use a less complex model as student model.
Hard and Soft Targets
Example reference: https://www.ttic.edu/dl/dark14.pdf
The labeled output in the dataset will be :

The ensemble model outputs will be like this using softmax function:

The output of the model after distilling its knowledge:

As we can see in the below figure, increasing the temperature gives us softened probabilities at the output layers thereby allowing us to extract the possible outputs.
Training Process
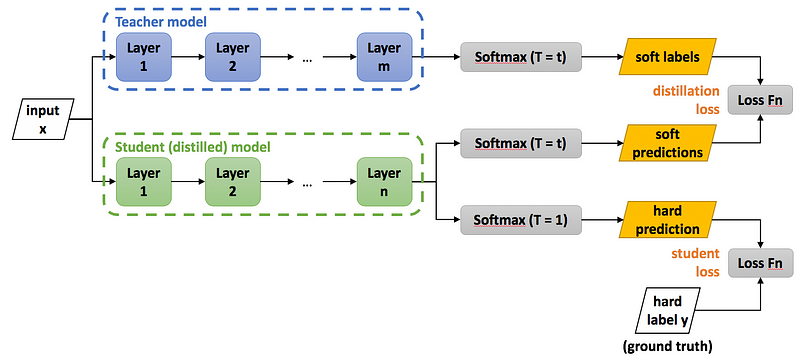
- The teacher network is trained on some dataset similar or not to the dataset to be used in student training.
- The teacher model and student model will be trained in parallel.
- The teacher model will have softmax with the temperature at the output layer and the student model will give two outputs. The output with softmax with temperature (Same T value as teacher network) and another output with standard softmax function at the output layer.
- The student model will be trained with the target of achieving the softened probabilities i.e., the output of teacher network (learning the knowledge learned by the teacher).
- The loss will be calculated together with both the models as L(X, W).
- The backpropagation will take place only on the student model because the teacher model is a pre-trained one and we are distilling the trained model to student. It needs to learn not the teacher model.
- This is a distillation process used to distill a complex model’s behavior to the much smaller model.
Loss Function Calculation
There are two objectives here
Cross entropy with soft targets:
The cross-entropy loss between teacher’s soft targets (softmax of teacher with temperature at T) and the student’s soft predictions (student model at the same temperature) is given by
L1 = H(σ(Zt;T=τ),σ(Zs,T=τ))
where,
σ(Zt;T=τ)-> softmax output of teacher model at T=τ
σ(Zs,T=τ)-> softmax output of student model at T=τ
Cross entropy with hard targets
The loss calculated between the output of student model and hard labels is to make the student model perform much better than teacher model in practice.
The cross-entropy loss between student’s hard predictions ( Student model with standard softmax) and the ground truth (true output labels) is given by
L2 = H(y,σ(Zs;T=1))
where,
σ(Zs;T=1)->standard softmax output of student model
y->true output labels
The final loss can be obtained by adding both loss
L(x;W) = α∗H(y,σ(zs;T=1)) + β∗H(σ(zt;T=τ),σ(zs,T=τ))
Hyper-Parameters
In general α, β and τ are hyper-parameters.
When the student model is very small compared to the teacher model, lower temperatures(τ) work better. Because as we raise the temperature, the resulting outputs will be richer in information, a small model cannot be able to capture all the information.
In the case of α and β, Hinton et al. use average between the distillation loss and the student loss. They have observed better results when keeping the α value much smaller than β.
Conclusion
This is the process of knowledge distillation and researches have introduced much better concepts in this domain. Knowledge distillation is different from transfer learning. In the case of transfer learning, the weights are transferred from a pre-trained network to a new network and the pre-trained network should exactly match the new network architecture. This means the new model will be as complex as the old model.
Thanks!
Comments
Post a Comment